PwC Scale #InsurTech programme - executive evening
Check the fotos






A marca "Data XL" é nossa!
POR OS NÚMEROS NO CENTRO DA COMPANHIA
No meio de legislação e normas, há às vezes algumas supresas: "Tenho a certeza que as seguradoras sabem que têm de ser mais do que uma commodity: o desafio está em como o ser..." - o meu artigo na newsletter da APS

The other side of the coin....
- "I want to optimize my price!"
- "Sure!, More revenue, more margin, more policies - what is your goal?"
- "Minimize the cost, subject to this renewal share"
Minimize cost! Yes! So obvious now!

Photo credits: By Andrè Bellingrodt - Own work, CC BY-SA 4.0, https://commons.wikimedia.org/w/index.php?curid=39375494
Proudly presenting Lazarus - our new product for winning-back former customers
Check out our business case simulator and let us know what you think!
*
You know that the client has left the company.
You know that it's necessary to present a lower price.
But how low should the price be?
Data XL allows insurers to setup the win-back price!
Brouchure here.
Business case simulater here.

Demo day - Pitch :: Dec - 2017

Our pitch for @F10_accelerator at #F10Demo: insurance pricing optimization!
HERE
Insurance Pricing Room is Live!!!! *vs1.0

"Get inspired by DataXL" by SIX
Hi!
Please check a quick interview made by SIX about Data XL
Every year F10 (powered by SIX) supports thirty startups to make the jump from idea to registered company. In this interview, for the internal the internal comm channel, SIX do not ask about business models, but about the people behind the ideas: "What drives them? Where do they find inspiration and how do they see the future?"
Hope you like it!
(a full transcript below)


**************
Every year F10 supports thirty
startups to make the jump from idea to registered company. In this weekly
series, we will not talk about business models, but about the people behind the
ideas. What drives them? Where do they find inspiration and how do they see the
future?
Here are 5 questions we asked to Filipe Charters de Azevedo who, when asked to compares his start-up with a fruit, choose a banana: because it would have a big smile and life is full of slippery falls.
- Who is the person that most inspires you and why?
The one person that has helped me most in my journey through life is, of course, my wife. But I do not want to be too sentimental in a business interview, so I will tell you about the books that have changed my professional view:
Information Rules: A Strategic Guide to the Network Economy, by Carl Shapiro and Hal Varian. They argue that if managers seriously want to develop effective strategies for competing in the new marketplace, they must understand the fundamental economics of information technology. I almost called the company "Data Rules," because of this book.
The Third Wave by Alvin Toffler allowed me a glimpse into the future. The book was written in the 1970s, and I am still surprised how accurate Toffler’s predictions of our time were.
2. How did you get the idea to start DataXL?
There was neither a eureka moment nor an apple falling on my head. The company is the product of a lot of thinking about how to combine expertise (experimental design), market (insurance and financial sector) and distribution (SaaS). Now it is easy to put in one sentence…
3. How is life in F10?
It is like being in the Erasmus program, but for grown-up entrepreneurs. At home in Portugal, after work, I would usually drink a coffee and eat a “pastel de nata” with my friends and colleagues. Here we drink beer!
4. Did you always want to become an entrepreneur?
I believe that
I’m what is called a T-person. The vertical bar on the T represents the depth
of related skills and expertise in a single field, whereas the horizontal bar
is the ability to collaborate across disciplines with experts in other areas
and to apply knowledge in areas of expertise other than one's own.
Usually people are “I” people: experts with
in-depth knowledge; a quality that companies appreciate and reward. But if you
have the ability to collaborate across areas it becomes easier to see the big
picture and create a company. Developing a new concept becomes the next natural
step. Becoming an entrepreneur is for most “T” people the only way to feel
satisfied.
5. Complete the following sentence: In five years' time…
…I'll have no regrets. Not even a few to mention.
Founder Box
Filipe Chartes de Azevedo (39) is a Portuguese entrepreneur with a background in consulting. Last year he founded the company Data XL, an online tool used for insurance pricing optimization.
Data XL is on PwC radar
Check it out!!!
"The breadth of InsurTech is impressive. The challenge for these new entrants over the next year is to start to scale. The challenge for incumbents is how to embrace these new players and fit them into new business models. Only then will the full potential of this transformation be realised and the InsurTech picture be clear."
source: https://www.linkedin.com/pulse/insurtech-started-blank-canvas-jonathan-howe/?trackingId=ZgbaBwrI8gMHizb8JP7fgA%3D%3D
How to refocus the PT ailing Workers Comp portfolio?

In Portugal, the Works Comp is stressing companies' results excessively. The problem is essentially a problem of tariff setting. "How to refocus the PT ailing Workers Comp portfolio?" is the question we try to answer.
It is a reflection on what can be done, presenting concrete measures.
All feedback is welcome.
---------------------------
Trata-se de uma reflexão serena sobre o que pode ser feito, apresentando medidas concretas.
Todos os contributos são bem vindos.
---------------------------
Insurance Princing Room
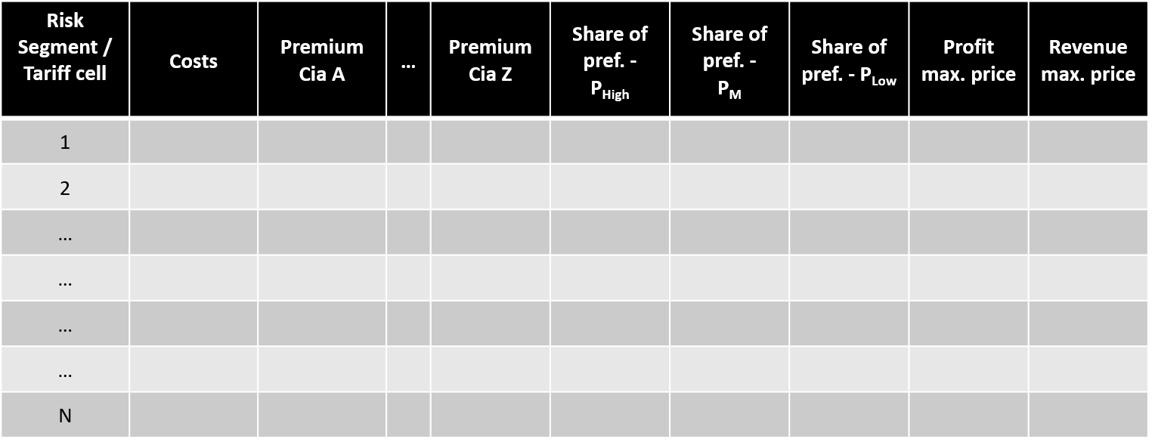
Our product was born from the need of Insurers to find out what customers value their products. With our solution, it is now possible for Insurers to identify which properties of their products do customers value the most and more importantly how much are they willing to pay for them.
Introducing Dynamic Pricing to Insurance - Meet Insurtech DataXL

We at Data XL help insurance companies to charge more if they can, less if they must.
We offer INSURANCE PRICE OPTIMIZATION WITH API.
@SuperDaveBruno! made a quick interview about our project on Data XL! Thank you for challenging us, to spread the message.
*
"DataXL can help you increase revenues by 2-4% in the first pilot. So if you're an Insurer looking for effective Insurtech Startups - you just found one. DataXL uses the same modern data analysis and logic applied by the big online retailers (eg. Amazon, eBay). Phil Charters, CEO of DataXL is helping bring Insurance into the digital age. DataXL uses algorithms during your renewals process to see where a customer perceives more value - and you can increase pricing.
.
My name is David Bruno and I am an entrepreneur, startup coach and investor."
DataXL - Value Based Pricing - Pitch

Have you ever wondered why an iPhone costs twice as much as a Samsung?
Correlation is not causation!
 Know one of our secret sources - and the limitations of using only internal data. This 2-minute video (kind of...) explains where and why Big Data cannot solve everything in an internal meeting at F10.
Know one of our secret sources - and the limitations of using only internal data. This 2-minute video (kind of...) explains where and why Big Data cannot solve everything in an internal meeting at F10.
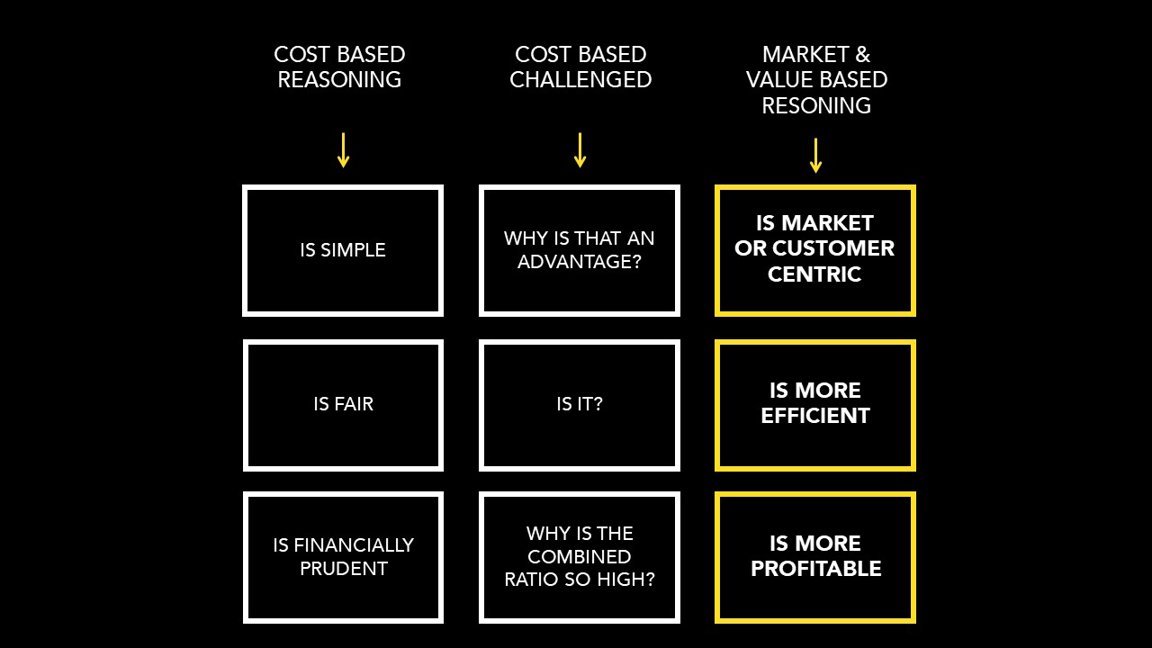
Let's challenge the Cost Based Reasoning
Cost-plus pricing is used primarily because it is easy to calculate and requires little information.
Insurance companies say it is fairer and financial prudent.
Check our views below!